今天我和大家讲一个算法,这个算法用于大量的文件存储和高速读取、备份。
大概这个算法是现在世界上最好的存储算法之一,原因是他的论文发在 SCI 上,现在还没有人写出一个比他好的算法。
SCI 是国际论文最顶级的发布地,所以质量还是可以相信。这个算法是理论上最好,实际使用可能需要修改好多。
因为我们公司遇到一个存储上的困难,做的产品好像是 PPT 一样的,但是要把所有的数据存放到自己的服务器,那么如何存在服务器可以让大量的用户存放不会出现明显的卡顿和已经存放了大量的数据,如何快速读取用户想要的数据。这就是我看到的问题。
因为我不是负责这一块,但我听说我师兄之前讲个的这个算法,于是拿过来用,至于是不是一个好的算法,我也不知道。
在实验室,可以不知道产品是怎样,设计出一个算法,并且说这是一个好的算法。但是在实际的开发,必须知道产品的需求,于是就不能直接使用算法,需要对算法进行修改。
看过 Hadoop 的算法,原来的 Hadoop 是不建议人们对传上去的文件修改。但实际上,可能是存在经常修改的文件。对于 Hadoop ,难以做历史记录,后来我问过另一个师兄,他说是可以做到的,不过渣渣不懂师兄说的如何做。
于是我想做的是一个支持修改的存储,可以无限历史还原,可以快速读取的系统。于是参见了惠普使用的方法,和之前听说的方法。这个方法没有实际去试,所以好不好,我也不敢说。
惠普的方法,主要是文件分块,其它的是如何存储。文件分块是为了:方便存储,第二是方便修改后的存储。这里需要说一些,对于一个很大的文件,需要把他分为多个小文件存储,不能自己存放大的文件。原因是当修改一个很大的文件一小点,如果不把一个大文件分块,就需要上传整个文件。一旦把文件分块,那么可以上传修改的块就好,至于修改上传的块之后如何去更新,这个在下面会说到。文件的分块不是可以随意分的,需要考虑分块的大小和分块之后是不是一次修改刚好会修改在多个块而不是在一个块。

那么我的文件分块是不是最难的,其实相反,文件分块是最简单的,刚好产品是PPT差不多的样子,一个页就可以分一块。
那么来说下算法是如何做:第一步,按照文件页,把文件分为多块。注意,这里的分块和存储的分块不是一样的,文件存储分块的层和他不在同一层。第二步,生成每个页的 ID ,生成的方法可以使用 sha 或 MD5加上作者和文件信息。注意,生成的 ID 是在全局要求极低的重复率。
那么存储的文件是什么,其实是一些 ID 。
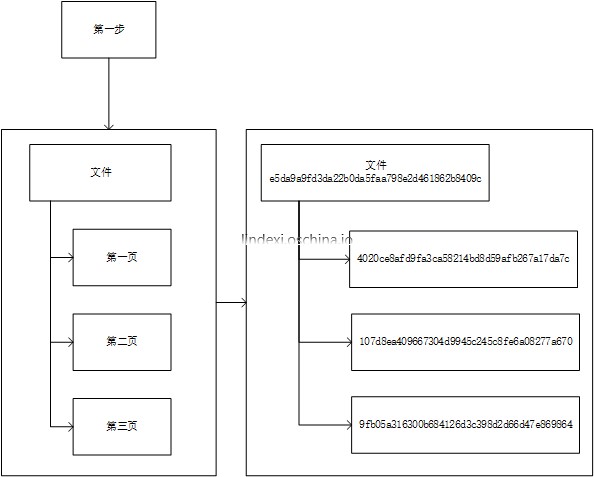
如果要获取文件,那么首先需要存储的是文件的 ID ,然后系统提供输入 文件的 ID 返回文件内容块 ID 的 API 。于是文件 ID 就可以获取文件块 ID 。系统还有一个 API ,输入文件块 ID 就可以获得文件块内容,于是可以用这个方法来获得文件。需要说的是,第一个 API ,返回文件块 ID 的那个 API 和第二个 API 其实是相同的。只是第一个 API 把文件块 ID 存储为内容,第二个 API 是把文件内容存储为内容。
这么做的好处:
- 用户经常的修改只有修改某些页,而且很多的文件都使用复制粘贴页,所以存在页的重复比较多,存储可以复用比较多。实际使用,我是推荐去挖掘一下一个用户存放的 文件 相同最多是什么,和所有用户存放的文件相同最多的是什么,这样来分块会比较好。
文件知道他的内容 ID ,不知道他的实际内容,于是多个文件存在相同的页面就会在系统只存在一个块,一个块提供多个文件引用。
- 对于用户修改某些页,可以通过上传用户更新的页,然后修改文件ID包含文件块ID的顺序等来更新文件。
如果用户文件ID包含了历史记录的属性,那么只需要把历史记录设为前一个版本的ID就好了,因为前一个版本的ID就记录了他的文件内容ID,这样可以只需要更新版本ID和更新内容ID就好了。
实际上因为和业务需求不同,所以这个算法是没有效率的。所有的文件都是小文件,假如有1k,里面重复最大的页只有 200b ,但是一个 ID ,其它的页,最小的只有 10b 于是,存 ID 的数据就比存数据的,有时候要大得多,所以这个方法最后不使用。
参见:
惠普使用的方法:http://www.hpl.hp.com/techreports/2005/HPL-2005-30R1.html
https://www.computer.org/csdl/trans/tc/2011/06/ttc2011060824-abs.html
本文会经常更新,请阅读原文: https://dotnet-campus.github.io//post/%E5%A4%A7%E6%96%87%E4%BB%B6%E7%9A%84%E5%AD%98%E5%82%A8%E5%92%8C%E5%A4%87%E4%BB%BD.html ,以避免陈旧错误知识的误导,同时有更好的阅读体验。
 本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
进行许可。欢迎转载、使用、重新发布,但务必保留文章署名
lindexi
(包含链接:
https://dotnet-campus.github.io/
),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请
与我联系
。
本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
进行许可。欢迎转载、使用、重新发布,但务必保留文章署名
lindexi
(包含链接:
https://dotnet-campus.github.io/
),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请
与我联系
。